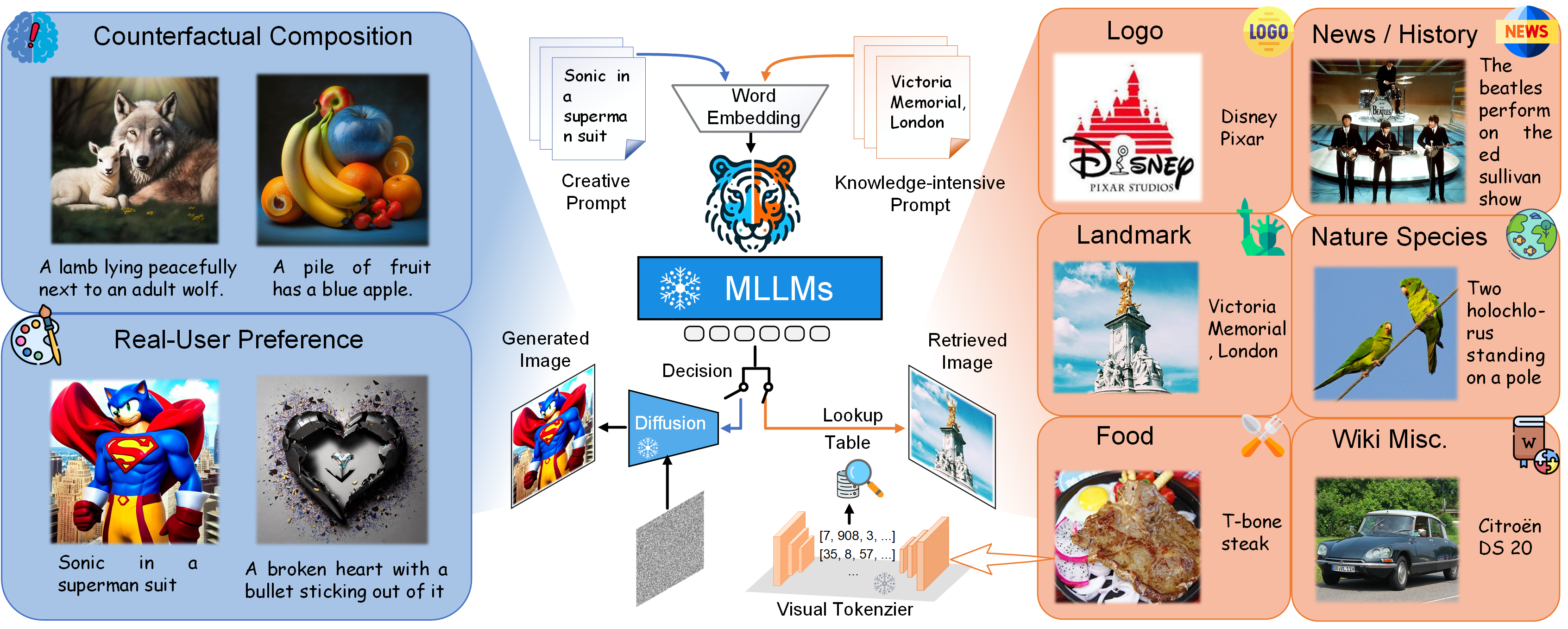
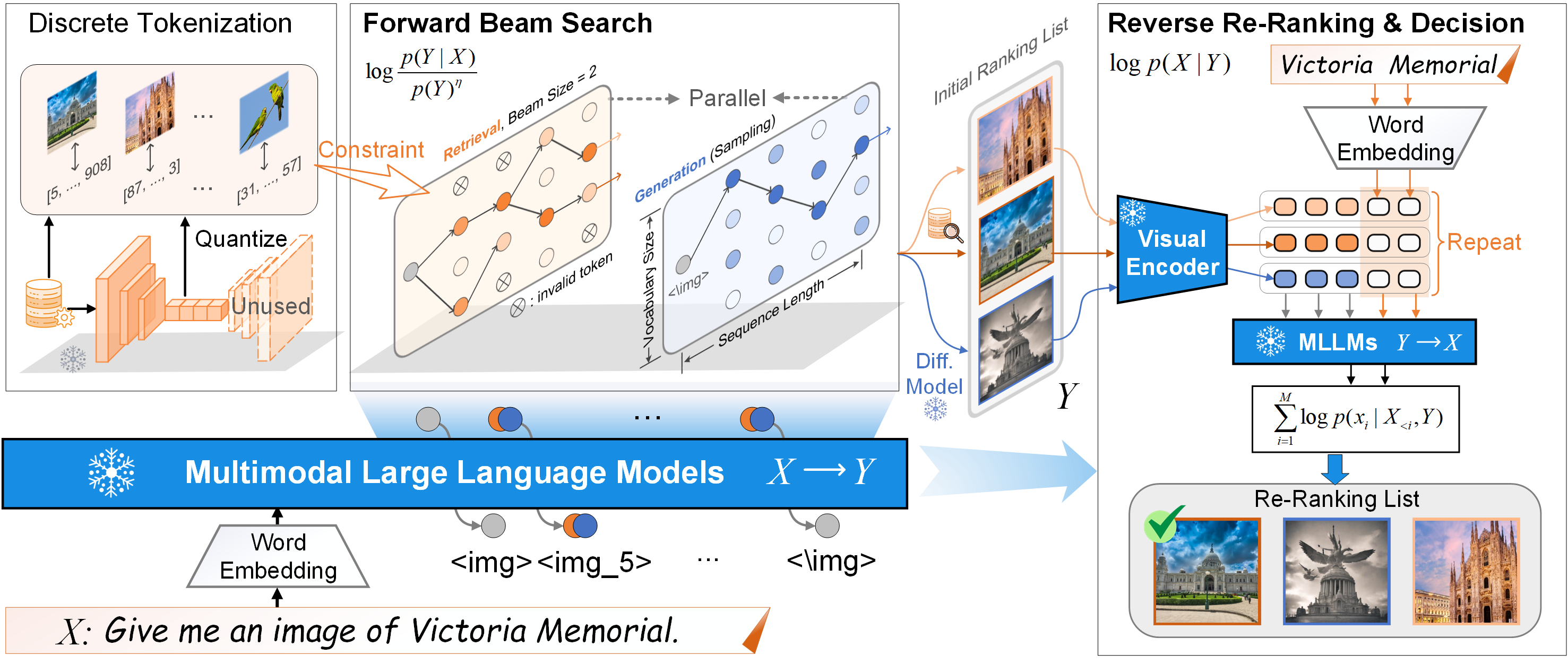
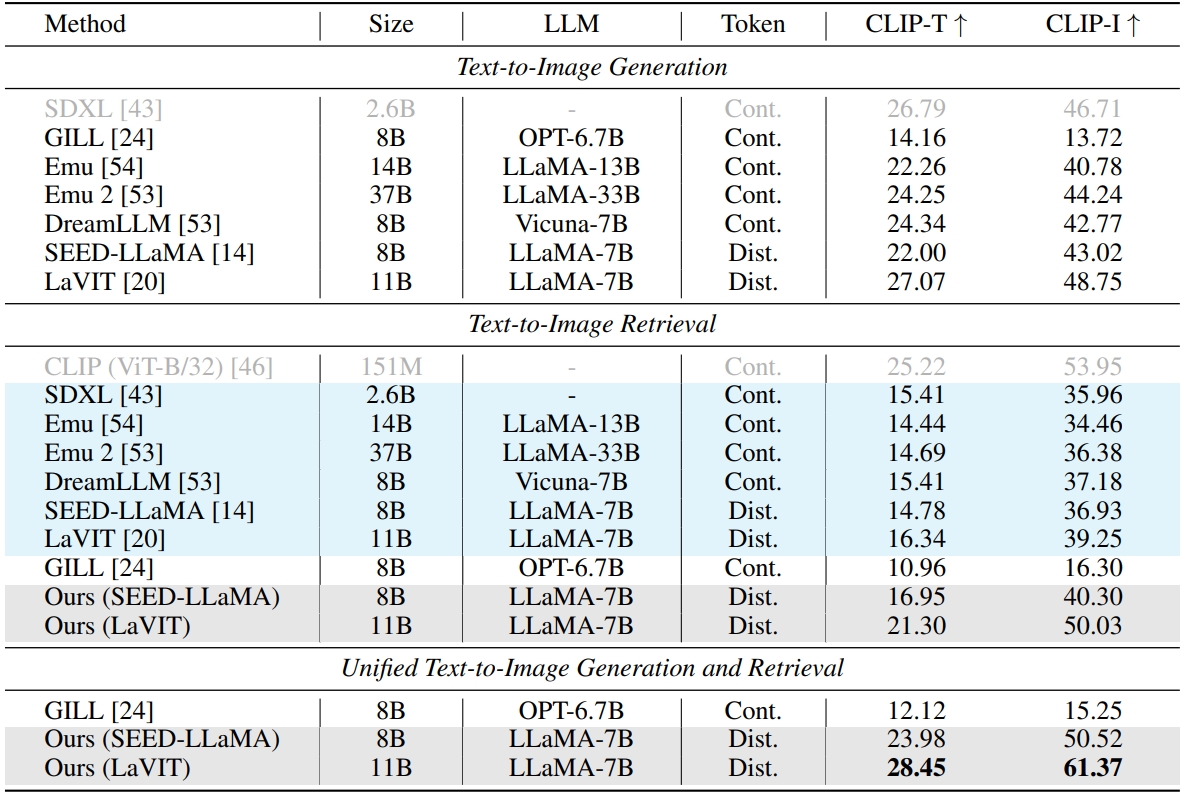
How humans can efficiently and effectively acquire images has always been a perennial question. A typical solution is text-to-image retrieval from an existing database given the text query; however, the limited database typically lacks creativity. By contrast, recent breakthroughs in text-to-image generation have made it possible to produce fancy and diverse visual content, but it faces challenges in synthesizing knowledge-intensive images. In this work, we rethink the relationship between text-to-image generation and retrieval and propose a unified framework in the context of Multimodal Large Language Models (MLLMs). Specifically, we first explore the intrinsic discriminative abilities of MLLMs and introduce a generative retrieval method to perform retrieval in a training-free manner. Subsequently, we unify generation and retrieval in an autoregressive generation way and propose an autonomous decision module to choose the best-matched one between generated and retrieved images as the response to the text query. Additionally, we construct a benchmark called TIGeR-Bench, including creative and knowledge-intensive domains, to standardize the evaluation of unified text-to-image generation and retrieval. Extensive experimental results on TIGeR-Bench and two retrieval benchmarks, i.e., Flickr30K and MS-COCO, demonstrate the superiority and effectiveness of our proposed method.